Metadata for transparent AI research and AI use
Metadata, rights, quality and versions – a history of the process in graphics
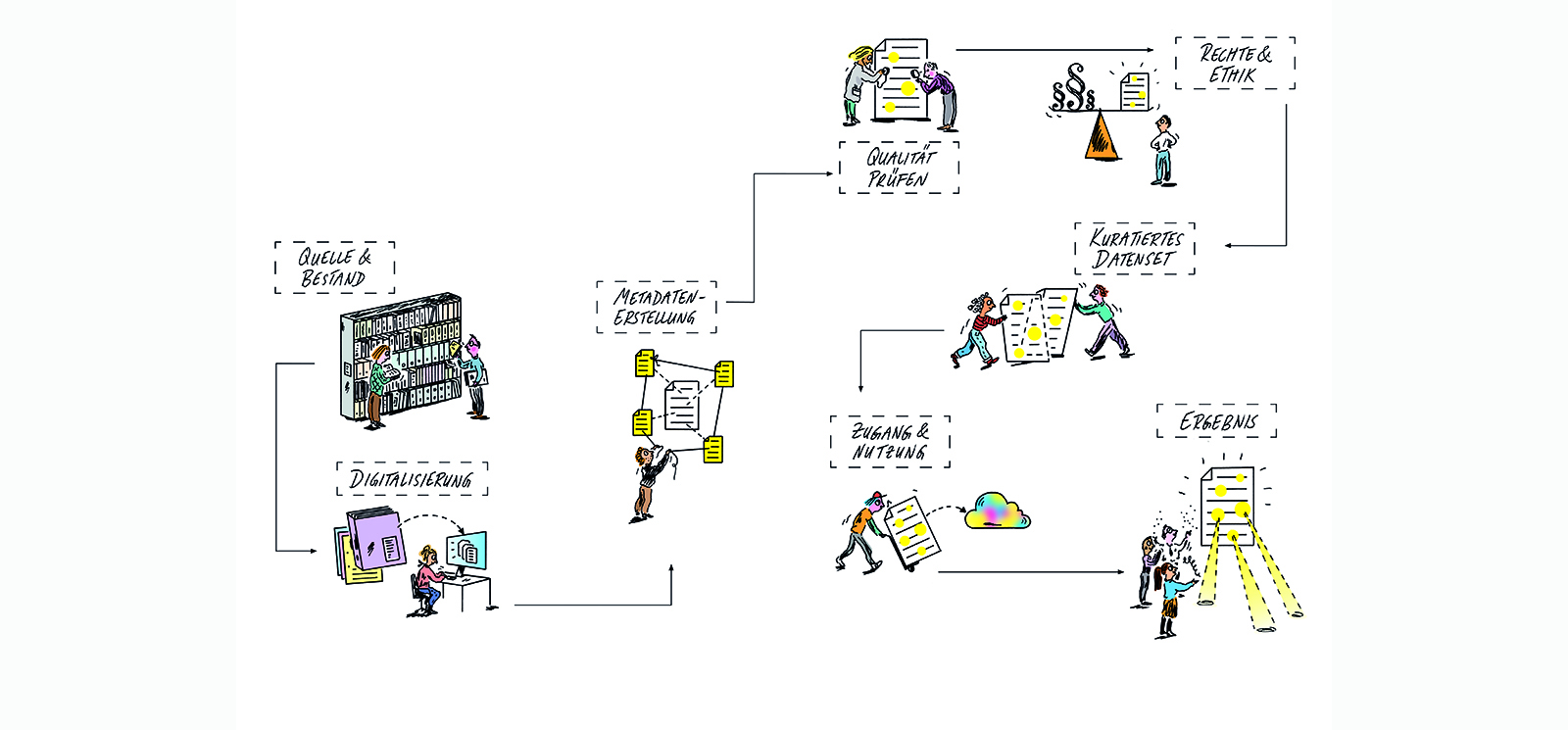
Illustration: Anne Vagt
AI-supported research becomes verifiable when data flows are visible. The illustration shows the documentation that must accompany a data collection so that research can contextualise and reproduce results. These include the chain of custody and provenance, rights and licence status, documented quality metrics, and uniquely referenceable versions. Libraries such as the ZBW can systematically record and provide this information, acting as an infrastructure linking collection, processing and re-use. Metadata is not merely accompanying text, but structured data about data. It follows syntactic and semantic rules and must be interchangeable between systems and domains, both technically and in terms of content. It is generated automatically or curated, and is continuously enriched and updated as the basis for collaborative work processes and data exchange within research infrastructures.
Metadata as a core function of a ZBW data infrastructure
AI methods are used in research to analyse texts, publication landscapes and digital collections, for example for thematic analyses, trend monitoring or linking publications to datasets. However, ‘text as input’ alone is not sufficient to produce reliable results. The crucial factor is whether the underlying database is described in such a way that it can be verified, cited and compared over time. In this context, metadata is not merely a supplement, but the infrastructural layer that enables discoverability, machine-readability and interoperability across systems. As structured ‘data about data’, metadata follows defined syntactic and semantic rules and must be interchangeable between systems and subject domains, both technically and in terms of content. It is generated automatically or curated and is continuously enriched and updated, serving as the basis for collaborative work and data exchange within research infrastructures.
In the form of standardised data and in combination with persistent identifiers, metadata also takes on a referencing and linking function. Individuals and organisations can be uniquely referenced, and digital cross-references to works, terms, research data and scientific software can be mapped in a stable manner. This mechanism also forms the basis for publishing metadata as Linked Open Data and integrating it into ontologies or knowledge graphs, in order to bring together many sources within integrated knowledge structures.
“Linked Open Data requires a higher level of semantic interoperability of standardised data,” explains Dr Andreas Oskar Kempf, a research fellow at the ZBW and an expert in taxonomy and thesaurus management. “Whilst controlled vocabularies used to be geared primarily towards use within one’s own collection, it is now crucial that concepts are modelled in a similar way so that different vocabularies can be linked together.”
Against this backdrop, the ZBW describes the generation of standardised, high-quality and structured metadata for publications as central to its role as an information infrastructure for the economic sciences. Metadata not only serves research purposes but is also regarded as a prerequisite for making collections reliably usable in data-intensive research settings. The ZBW plays a key national role in this regard for the field of economics. It already produces the vast majority of economic metadata in Germany. Consequently, requirements for quality, consistency and interoperability are directly linked to day-to-day operations.
Central to this is the ZBW’s commitment to optimising metadata in future not only for human use, but also for machine processing and integration into semantic web environments. Key components of the ZBW’s metadata infrastructure include, on the one hand, adherence to established metadata standards (including Dublin Core and MARC21), on the other hand, the use of persistent identifiers, in particular DOIs via DataCite, as well as traceability and long-term referencability, and finally, linked data architectures and open interfaces to enable technical and semantic interoperability with external systems.
Anke Böhrnsen, who heads the Integrated Acquisition and Cataloguing Department at the ZBW, emphasises that these elements are relevant not only in terms of infrastructure but also from an analytical perspective. “The high data quality at the ZBW is based on the consistent enrichment and linking of its datasets – a key step in enabling bibliometric analyses and ensuring the long-term viability of the data as Linked Data.”
From keyword to machine-readable context
The ZBW processes its metadata in such a way that it can be used in a variety of ways. In addition to bibliographic details, structural and semantic information is also recorded – that is, information about content and the relationships between them. This allows data to be linked more effectively, for example between publications, researchers and topics. An important foundation for this is the Standard Thesaurus of Economics (STW) developed by the ZBW, an open, controlled vocabulary for economic terms. The STW is the world’s most comprehensive bilingual specialist vocabulary, covering all areas of economics and key related subject fields.
Dr Lena Dolud, a research associate at the ZBW, explains: “The STW provides stable terms and relationships which we embed in metadata and make interoperable via mappings – for example, to the Gemeinsame Normdatei (GND) – so that topics remain consistently referenceable across collections, systems and languages, and can be reused in a variety of ways by the economics research community and on the Semantic Web.”
Technical interoperability as a goal
For the ZBW, the components described are not merely architectural decisions, but prerequisites for interoperability. Metadata should be made available in such a way that it can be used in external infrastructures, toolchains and analytical environments, including where data from different sources is consolidated. This also aligns with the infrastructure objective of establishing interoperable metadata as the basis for the integration, distribution and exchange of knowledge.
Automation with quality assurance
For ongoing metadata production, the ZBW relies on automation to enable the timely cataloguing of increasing volumes and heterogeneous resources. Central to this are AI-supported cataloguing workflows, which are combined with a ‘human-in-the-loop’ approach to ensure quality and oversight. This links operational scalability with the requirement to maintain control over metadata as a reference and verification layer.
As Dr Argie Kasprzik from the ZBW explains, whilst automation helps to catalogue large volumes, responsibility is not left to the system alone. Dr Argie Kasprzik explains: “We combine automated enrichment based on machine learning methods with fine-tuning using intellectually annotated data and randomised expert review – that is our ‘human-in-the-loop’ principle.”
Integrating external metadata, reconciling differences
A recurring challenge is the integration of external metadata, as many data infrastructures lack sufficient quality or standardisation in the metadata they provide. This hinders seamless interoperability and limits the usefulness of aggregated datasets. The ZBW regards addressing these discrepancies as a key task within its metadata strategy – involving ongoing harmonisation and alignment work in line with standards, mappings and quality requirements. Dr Timo Borst, Head of the Department of Innovative Information Systems and Publication Technologies at the ZBW: “For AI research or information science research, it is not only what is contained in the dataset that matters, but what we can verify about it – namely: its origin, version, quality standard and usage rights. For us, metadata is the reliable point of reference.”
This text was written in March 2026.
This text was translated on 25 June 2026 using DeeplPro.